-
2. 기계학습의 분류Deep Learning/Fundamentals 2020. 2. 21. 23:28
Review
지난 글에서는 인공지능, 기계학습, 딥러닝의 개념과 개념 간의 차이점을 알아보았다. 간단하게 다시 정리하여보면 다음과 같다. 인공지능은 인간의 사고방식을 모방하는 기계를 구현하는 것을 총칭하며, 기계학습은 경험으로부터 학습할 수 있는 소프트웨어를 구현하는 것이다. 또한 딥러닝은 깊게 쌓은 기계학습 모델로 특정 분야에서 인간을 뛰어넘은 능력을 구현하는 것이다.
우리가 정리한 '딥러닝'의 정의로 부터, 딥러닝에 대해 공부하기 위해서는 먼저 기계학습에 대해서 이해해야한다는 것을 알 수 있을 것이다. 깊고 복잡한 딥러닝 모델이 어떻게 생겼는지 알아보기 이전에, 기계가, 즉 소프트웨어가 무언가를 학습한다는 것이 무엇인지 이해할 필요가 있다.
기계학습 모델의 개요

이 그림은 일반적인 기계학습 모델을 시스템의 관점에서 표현한 그림이다. 먼저 위의 그림에서 등장하는 기호들의 의미에 대해서 알아보자. 모든 기계학습 모델은 입력되는 데이터 $x$에 대해서 출력값 $\hat{y}$을 가지는 함수로 볼 수 있다. 이 함수를 가설 함수(hypothesis function)이라고 한다. 가설 함수 $h$는 파라미터 $\theta$를 가지고 있으며, 파라미터의 값에 따라 가설 함수의 출력 $\hat{y}$이 달라진다. 이 출력값 $\hat{y}$은 모델의 예측값(predict)라고도 불린다. Supervisor $y$는 입력 데이터 $x$에 대응되는, 모델이 예측하기를 기대하는 참값이다. 결국 모델을 학습시킨다는 것은 예측값 $\hat{y}$이 참값 $y$에 비슷해지도록 $\theta$를 조절해나가는 것이며, 이것이 기계학습의 전부이다.
기계학습의 분류
기계학습은 크게 세가지로 분류될 수 있다.
- 지도 학습 (Supervised learning)
- 비지도 학습 (Unsupervised learning)
- 강화 학습 (Reinforcement learning)
학습의 특징을 나타내는 주요 변수들을 나열하면 다음과 같다.
알고 있는 것 모르는 것 지도 학습 $x$, $y$ $\theta$ 비지도 학습 $x$ $y$, $\theta$ 강화 학습 $x$, $s_1, s_2, \cdots$ $a_0, a_1, a_2, \cdots$ 각 분야에 대한 자세한 설명을 아래에서 계속하겠다.
지도 학습

비선형 분류 모델(좌)과 선형 회귀 모델(우)의 학습 결과를 시각화한 것이다. 지도 학습은 데이터셋과 함께 참값(예: 결과 또는 라벨)을 사용하여 모델을 학습시킨다. 데이터셋과 참값을 통해 학습된 후에는, 학습 이전에 보지 못했던 새로운 데이터에 대한 답을 찾을 수 있어야 한다. 학습 알고리즘은 그러한 결과를 얻기 위해 과거의 경험을 이용한다. 위의 표에서 지도 학습에서는 입력 데이터 $x$와 그에 대응하는 참값 $y$를 알고 있으며, 이를 통해 최적의 파라미터 $\theta$를 찾는 것이 목표라고 할 수 있다. 지도 학습이 활용되는 대표적인 문제로 분류 문제(Classification)과 회귀 문제(Regression)가 있다.
비지도 학습
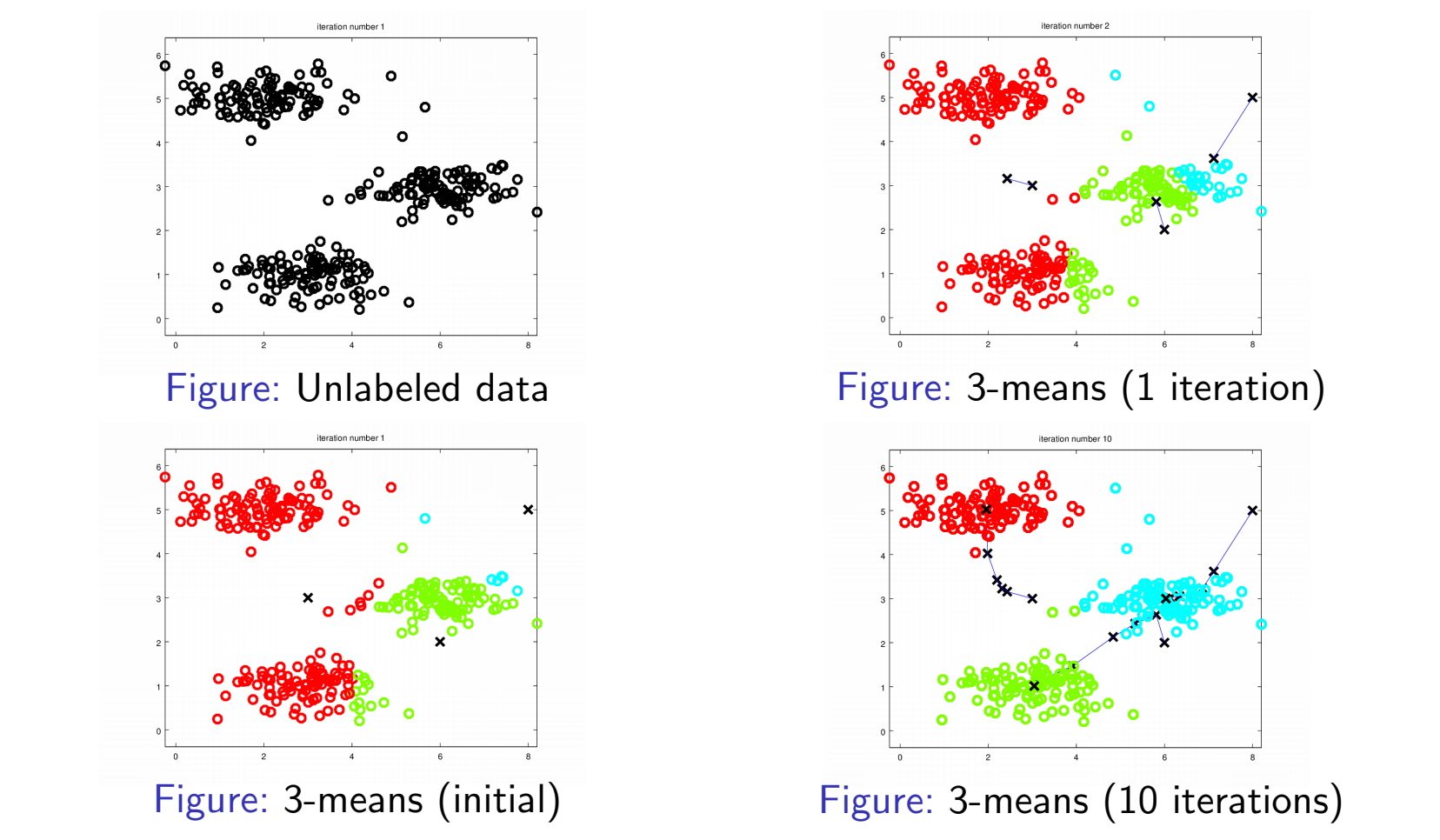
대표적인 군집화 모델 중 하나인 K-means의 학습과정을 시각화한 것이다. 비지도 학습은 라벨이 표시되지 않은 데이터셋를 사용하여 모델을 학습시킨다(즉, 제공된 데이터셋에 대해 참값을 알 수 없음). 즉, 학습 알고리즘은 주어진 데이터셋이 무엇을 나타내는지 사전에 알지 못한다. 위의 표에서 비지도 학습에서는 입력 데이터 $x$만을 알고 있으며, 그에 대응하는 참값 $y$을 알 수 없다. 입력 데이터만을 통해 최적의 파라미터 $\theta$를 찾는 것이 목표라고 할 수 있다. 비지도 학습이 활용되는 대표적인 문제로 군집화 문제(Clustering)과 차원 축소 문제(Dimensionality reduction)가 있다.
강화 학습
강화학습은 소프트웨어 에이전트가 누적 보상(Reward)을 극대화하기 위해 환경(Environment)에서 어떤 행동(Action)을 취해야 하는지에 대한 학습이다.
'Deep Learning > Fundamentals' 카테고리의 다른 글
1. 인공지능과 기계학습, 그리고 딥러닝 (0) 2020.02.05 0. 딥러닝 첫 걸음 (0) 2020.02.04